This is a fantastic resource that has been made publicly available by Cetis, The Centre for Educational Technology, Interoperability and Standards, and the author Phil Barker has generously allowed any copying, distribution of his work, if you need to utilise it for yourself. (maybe to convince/educate business partners, staff etc).
To simplify things for readers, I have taken the definition, and then shown uses and visual examples which will hopefully make more sense and open peoples eyes to the implications and reality of having structured data (of any type) on your website. The full briefing can be found here. h/t to Aaron Bradley where I saw this, and is the font of all Semantic Knowledge!
What is Schema.org?
Schema.org is a joint initiative by Google, Yahoo, Microsoft Bing and the Russian
search engine Yandex, which was launched in June 2011.
The aim of the initiative is to help search engines to interpret information on web pages so that it can be used to improve the display of search results, making it easier for people to find the information they are looking for.
To do this, content publishers insert machine readable information into the HTML of web pages that helps search engines understand the significance of the text on those pages. This information helps to identify which text is the title, which is the author’s name, which link is to the publisher, etc.
In other words, it allows human readable resource descriptions to double up as machine readable metadata, or what Google calls structured data.
Uses of schema.org metadata
If schema.org metadata is available, any search engine may use it to improve their search interface, for example:
• by distinguishing between different things with the same name (e.g. a book, a film and a game)
• by allowing the most relevant information to be displayed more prominently on the results page
• by enabling results to be filtered by properties such as price, supplier or publication date
• by providing links to more results about the same subject or from the same publisher
An example of such an interface can be seen on Google Shopping, as illustrated below. (We must note that Google probably gets the data for creating such interfaces from many sources not just schema.org metadata.)
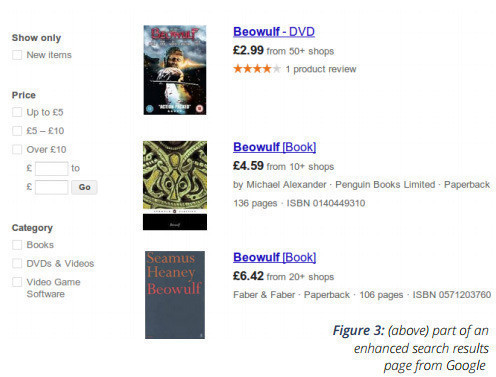
The full cetis presentation can be viewed and/or downloaded here: What is Schema.org?
But I thought I'd add a couple more examples of schema.org structured data in action.
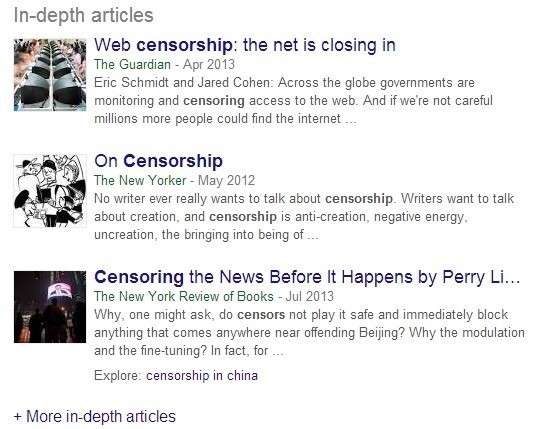
Indepth Articles: Just Google Censorship to replicate.
Or select news in Google search and type chickens
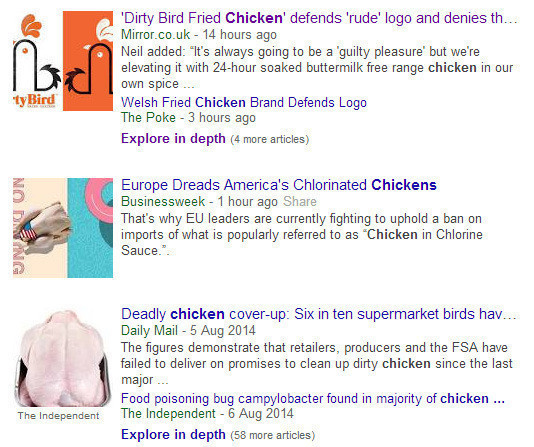
To understand how Google selects the Mirror "Dirty Bird Fried Chicken.." article, and what image to display, title etc. Then it's worth looking at the schema.org code relating specifically to that article:

So in simple terms, the Mirror content writers have simply told all the search engines very simply what their article is about, when it was published, the title etc.
That doesn't mean a search engine will elect to use your exact text, as in this example, Google has used a different description text, in the same way it does with your own website, and sometimes ignores your meta description tag.
But if all of your content was laid out like this, then you are starting to explain to search engines what your web page is all about, and if it is the best resource to answer a question, or respond to an enquiry.
Here is what the search engines can see for this particular page:

The days on simply relying on keywords getting picked up in your web pages and title tags aren't quite dead just yet, but they are certainly fading. Structured data is now firmly established across all the search engines and will become more and more important as the months and years roll by.
If you are looking to build a new website or refresh your current one, then it's time to make sure your pages are marked up with structured data, and your web designer is up to speed with current practices.
If anyone wants to discuss structured data, has any opinions, good or bad, needs help or just advice, then fire away.






